TL;DR
Go’s native fuzzing library has simplified embedding fuzzing harnesses, but strategic planning is key to effective fuzzing efforts. By using Wally, we can identify critical paths and evaluate the impact of panics, ensuring our fuzzing efforts are both targeted and efficient.
Exposition
While Go-fuzz was and continues to be an approachable tool for writing fuzzing harnesses, the introduction of the native fuzzing library in Go 1.18 made fuzzing increasingly easy and developer-friendly. Since Go 1.18, developers can easily embed fuzzing harnesses within their unit test files without including any new libraries.
Interestingly, fuzzing in Go often requires more planning compared to fuzzing a C++ library with libFuzzer. Several techniques, like differential fuzzing to compare two routines (from different libraries) with a similar function or round-trip fuzzing to ensure that, for instance, your decoders and encoders are consistent with each other, are available. However, unless you are focusing on low-level libraries and cgo code, testing for a simple panic to find common bugs such as nil dereferences and out-of-bound indexes can often be less useful in a garbage-collected programming language. Unlike C, where a panic discovered through fuzzing can lead to RCE bugs of various complexity, a panic in Go more often than not allows you to find an availability bug—that is, a bug that could cause the application to crash, become unresponsive, or hang. Moreover, many developers now use fault tolerance patterns to protect their code against panics, making the exploitability of simple panics discovered through fuzzing less practical in real-world scenarios.
The Go HTTP server is a great example of this. If you write an HTTP server using the net/http library and one of your HTTP handlers has a nil dereference, a panic will be recovered, and the user may at worst see a 500 error code, but the application will continue running as normal (you can find the recover() calls here and here). Similarly, you’ll find other middleware libraries that help make your code fault-tolerant, Failsafe-go being a particularly nifty example, as it can help protect your application against several fault conditions. The point here being: even if you find a simple panic via fuzzing, does it matter if your application will be recovered by a middleware or even a recover block such as the one below?
func handleRequest(word string, idx int) {
defer func() {
if r := recover(); r != nil {
fmt.Println("Recovered in f", r)
}
}()
CallPanickyFunc(word string, idx int)
}
func CallPanickyFunc(word string, idx int) {
letter := word[idx]
fmt.Println(word, letter)
}
Just in case you are already judging me as a lazy developer—as a developer, my answer is “of course it does, let’s fix it.” Regardless of whether a panic could be caused, a developer should care about correctness and proper error handling (there is a joke here about error handling in Go I should probably not get into at the moment though). However, as a security researcher, if I find this bug while fuzzing a codebase and I know that CallPanickyFunc can only be called from handleRequest, I am likely to rate it as informational. Yes, there is a bug, but it’s a programming error that if triggered at runtime would not cause loss of the good ol' CIA (confidentiality, integrity, availability). The only reason I would rate it any higher is, say, in the case that the code is so complex that CallPanickyFunc could be called from unexpected places or from an unknown library.
This is where planning and careful consideration for your fuzzing efforts come in. It doesn’t make sense to write a fuzzing harness for any function simply because it looks fuzzable like a decoder or encoder. In fact, I’d admit spending unnecessary time and CPU resources fuzzing functions that I later realize fit this category—they can only be reached from a call path that will prevent the panic. This is where Wally can come in to help.
Planning fuzzing efforts with wally
Recently I was evaluating some microservices code in a monorepo and found several functions that seemed like good fuzzing targets due to their complexity and the type of data they handle. However, before fuzzing just for fuzzing’s sake, I wanted to answer the following:
- What are the different ways in which this function can be reached?
- For instance, can it only be reached via a gRPC or HTTP call that eventually lands at the target function, or is there some other process (say, a task run daily by a different process) that can call it with user input (e.g., pulled from a user database) via a different call path?
- If I find a panic here, how much would it matter? That is, would this be recovered by a function in the call path with a
recover()in adeferblock?
Answering the above was key in determining where to spend my fuzzing efforts. Moreover, if I could find such answers, if I were to find a panic, I could then be able to say “if the user can supply their input via this path, the server will crash,” which is important to answer the “so what?” once I reach out to the developers and propose a fix.
To this goal, I made several updates to Wally and added two key features:
- It is now possible to point Wally to a single function from the CLI (rather than a YAML file)
- Wally can now tell you which paths to a target function will recover in case of a panic triggered by that target function.
Note: As an aside, I also modified the algorithm for mapping call paths in Wally to use BPF instead of DFS, but the reasons for that are worth a separate blog post.
Let’s give this a try. Say we are interested in fuzzing the Parse function. In particular, we are interested in how it is used by Nomad. Even if we find a panic, we’d want to know whether there are any functions in Nomad that would call it and potentially cause Nomad to crash. To do this analysis with Wally, we’d run the command shown below from the root of the Nomad directory.
$ wally map search -p ./... --func Parse --pkg github.com/hashicorp/cronexpr --max-funcs 7 --max-paths 50 -f github.com/hashicorp/ -vvv
-p ./...: Target code is in the current directory--func Parse: We are interested only in theParsefunction--pkg github.com/hashicorp/cronexpr: Of packagegithub.com/hashicorp/cronexpr--max-funcs 7: We only want up to 7 functions per path--max-paths 50: Limit the paths to 50-vvv: Very, very verbose-f github.com/hashicorp/: This tells Wally that we are only interested in paths within packages that start withgithub.com/hashicorp/. This avoids getting paths that reach beyond the scope we are interested in. Otherwise, we’d get nodes in standard Go libraries, etc.
The result gives us 28 paths. The screenshot below shows a section of the paths
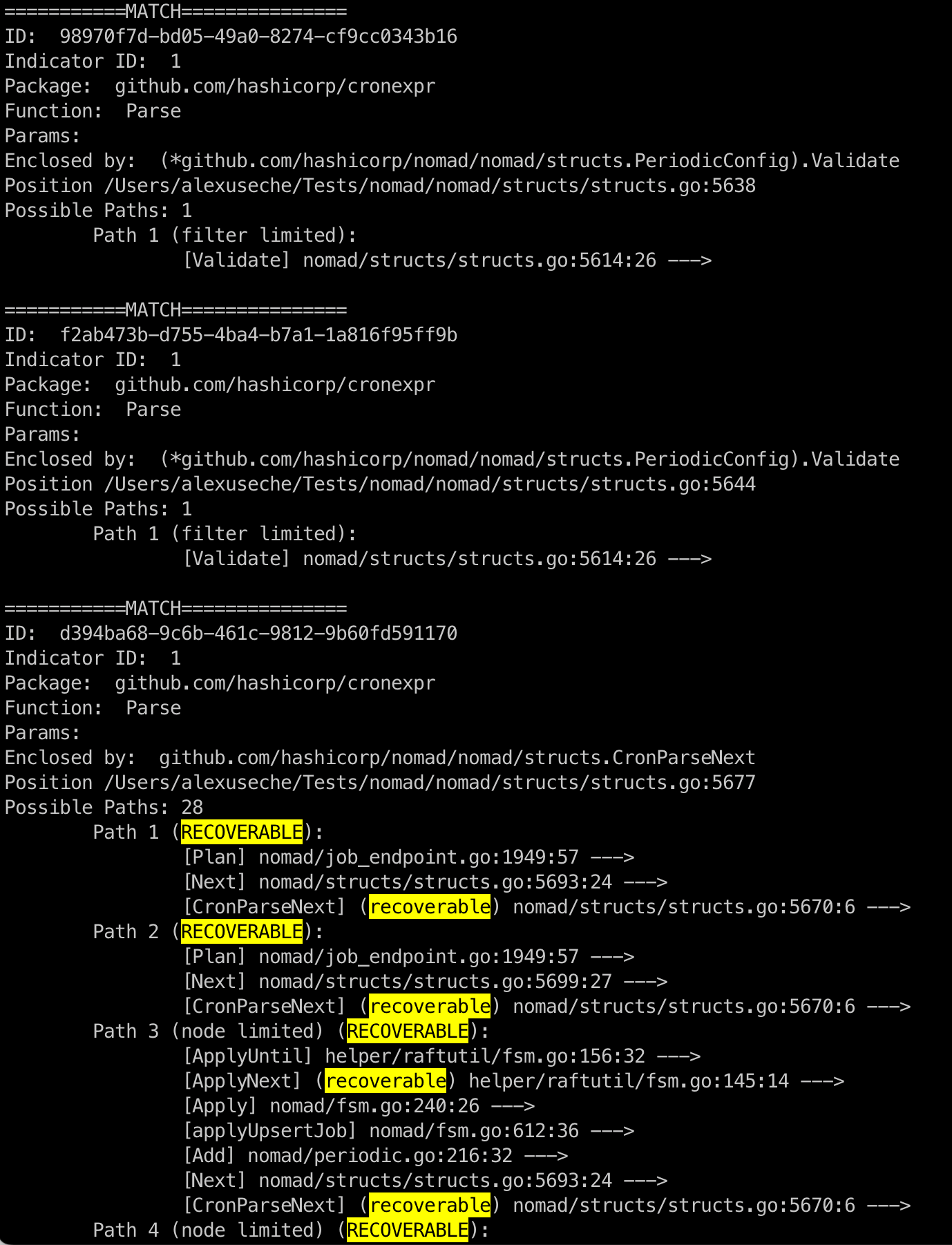
The first two paths point to two functions found here and here. Both are enclosed by the same Validate function, which is why we see the same node for both matches. If we examine those functions, there is no defer block calling recover. The rest of the paths are marked as recoverable and start at nomad/structs/structs.go:5677, enclosed by CronParseNext. The path is also marked as recoverable, which tells us that an application crash is unlikely if the Parse function in question is called from these paths. If we take a look at the function body it looks like this, confirming the output.
func CronParseNext(fromTime time.Time, spec string) (t time.Time, err error) {
defer func() {
if recover() != nil {
t = time.Time{}
err = fmt.Errorf("failed parsing cron expression: %q", spec)
}
}()
exp, err := cronexpr.Parse(spec)
if err != nil {
return time.Time{}, fmt.Errorf("failed parsing cron expression: %s: %v", spec, err)
}
return exp.Next(fromTime), nil
}
Another example
Let’s look at another example. Say we have this code (available here):
package main
import (
"github.com/hex0punk/wally/samppleapp/printer"
"github.com/hex0punk/wally/samppleapp/safe"
)
func main() {
word := "Hello"
idx := 7
printCharSafe(word, idx)
printChar(word, idx)
}
func printCharSafe(word string, idx int) {
safe.RunSafely(func() {
printer.PrintOrPanic(word, idx)
})
}
func printChar(word string, idx int) {
printer.PrintOrPanic(word, idx)
}
The function safe.RunSafely simply calls a given function and calls recover() in case of a panic:
package safe
import "fmt"
func RunSafely(fn func()) {
defer func() {
if recovered := recover(); recovered != nil {
fmt.Printf("recovered by safe.Wrap - %v\r\n", fn)
return
}
}()
fn()
}
Lastly, the PrintOrPanic function looks like this:
package printer
import "fmt"
func PrintOrPanic(word string, idx int) {
letter := word[idx]
fmt.Println("letter is ", letter)
}
As a security engineer, let’s pretend you are interested in fuzzing PrintOrPanic (I know you can spot the bug, but play along here, this is for demonstration purposes) but perhaps you’d like to run it from a call earlier in the stack to test for realistic scenarios that could cause an application crash. Let’s go ahead and run Wally and determine which path would make the most sense to fuzz (or at least, to determine whether a panic would be realistic)
$ wally map search -p ./... --func PrintOrPanic --pkg github.com/hex0punk/wally/samppleapp/printer -f github.com/hex0punk/wally/samppleapp -vvv
The results are shown below
===========MATCH===============
ID: f9241d61-d19e-4847-b458-4f53a86ed5c5
Indicator ID: 1
Package: github.com/hex0punk/wally/samppleapp/printer
Function: PrintOrPanic
Params:
Enclosed by: github.com/hex0punk/wally/samppleapp.printCharSafe$1
Position /Users/alexuseche/Projects/wally/sampleapp/main.go:17
Possible Paths: 1
Path 1 (RECOVERABLE):
main.[main] main.go:11:15 --->
main.[`printCharSafe`] main.go:16:16 --->
safe.[RunSafely] (recoverable) safe/safe.go:12:4 --->
main.[printCharSafe$1] main.go:16:17 --->
===========MATCH===============
ID: eb72e837-31ba-4945-97b1-9432900ae3f9
Indicator ID: 1
Package: github.com/hex0punk/wally/samppleapp/printer
Function: PrintOrPanic
Params:
Enclosed by: github.com/hex0punk/wally/samppleapp.printChar
Position /Users/alexuseche/Projects/wally/sampleapp/main.go:22
Possible Paths: 1
Path 1:
main.[main] main.go:12:11 --->
main.[printChar] main.go:21:6 --->
Total Results: 2
The results can be interpreted as follows:
- There are two matches here, as there are two uses of the
PrintOrPanicfunction. - The first use is via
printCharSafe$1; the call starts at the place indicated by thePositionfield,sampleapp/main.go:22. - If we navigate the flow from top to bottom, we can see how the call starts in the
mainfunction, followed byprintCharSafe, which callsRunSafely. In effect, if we look at the definition ofRunSafelyabove, we can confirm this. - Importantly, this is marked as
recoverable. This tells us that any call path that goes through here will recover if a panic occurs. - Lastly, we reach
printCharSafe$1. The$1is just an indication that the Go call graph library is giving us that there is an anonymous function inside ofprintCharSafe$1. - The second match is not marked as
recoverable, indicating that a call toPrintOrPanicviaprintCharcould lead to an application crash in the case of errors like nil dereferences.
This information alone should help us target specific functions and call paths to fuzz. Moreover, if we found a panic by fuzzing PrintOrPanic, we now know what the most critical path is when we evaluate the risks.
Caveats
There are some interesting caveats that are for the most part due to how the different algorithms available for constructing call paths via golang.org/x/tools/go/callgraph/.
By default, Wally uses the cha algorithm for constructing the program call graph. It later uses custom logic to create what is relevant from the call graph based on user input using either BFS or DFS to search through the generated graph. Per the documentation, cha may:
“include spurious call edges for types that haven’t been instantiated yet, or types that are never instantiated."
Another important point is the following about CHA:
“it is sound to run on partial programs, such as libraries without a main or test function."
While this makes it an ideal algorithm for most programs, in part because it will map the usage of library functions that don’t necessarily trace back to main, it also means that we may get some execution paths that could be possible but aren’t if we consider the root of the program being main and init functions. This becomes more evident when Wally gathers a large number of paths. In those cases, the more paths you get, the more careful examination of the results is necessary. However, there are some checks that Wally makes to limit those so-called “spurious” call paths:
- Whenever Wally sees it reaches a
mainfunction, it will stop going further back in the tree to avoid reporting inaccurate paths. If you wish, you can override this by using the--continue-after-mainflag, allowing you to see some interesting but less likely paths. - Using the filters provided by
-fyou can keep Wally at bay by telling it to not reach functions beyond a specific Go module or module prefix. - You can also limit the number of paths per finding using
--max-paths, as well as the number of functions per path using--max-funcs. - You can test with other algorithms using
--callgraph-alg. This is the algorithm used by thegolang.org/x/tools/function. Options includecha,rta, andvta. - Lastly, you can ask Wally to use DFS instead of BFS for its custom, core call mapper logic, using
--search-alg dfs. This may aid you in your analysis depending on the size of the code you are analyzing.
Wrap up
I hope you find these features useful. I have certainly been enjoying working on Wally, and have been finding it useful in planning my fuzzing and code analysis endeavors. If you have a suggestion for a change, open an issue in the Wally repo, or even better, create a PR.